
what’s mean of tests number and files?
In src there’s usually single class and/or utilities in a single file. You want to have unit tests covering them, so number of test files should correlate to number of source files (i.e. number of test files should be >= number of source files). In our case it’s higher due to few things:
- some things are in headers only (i.e. interfaces, templates) – that’s why number of headers in
srcis larger than number of files (124 vs 203) – you want to test them as well - tests, usually require some utility functions/classes, which we have separated – since tests on their own do not require separate header files, you can estimate, that number of files with utility functions/classes is 56, therefore (estimated) number of test files would be around ~162
= (218 - 56) - as mentioned earlier by bloodyrookie, we also have integration tests
I’ll see if I can come up with some stats, how many classes do we have and how many classes are tested, but our coverage is pretty good.
3 Likes
thx for the explanation. 
those explanation is very useful 
from these files/stats/tests are you able to give a rough % done on Catapult?
For example you expect code SUM ~ 35,000 when complete. so 50% done atm?
not really possible to do that. current state would be like this:
we have working network with basic transactions, but we need:
- find and fix bugs
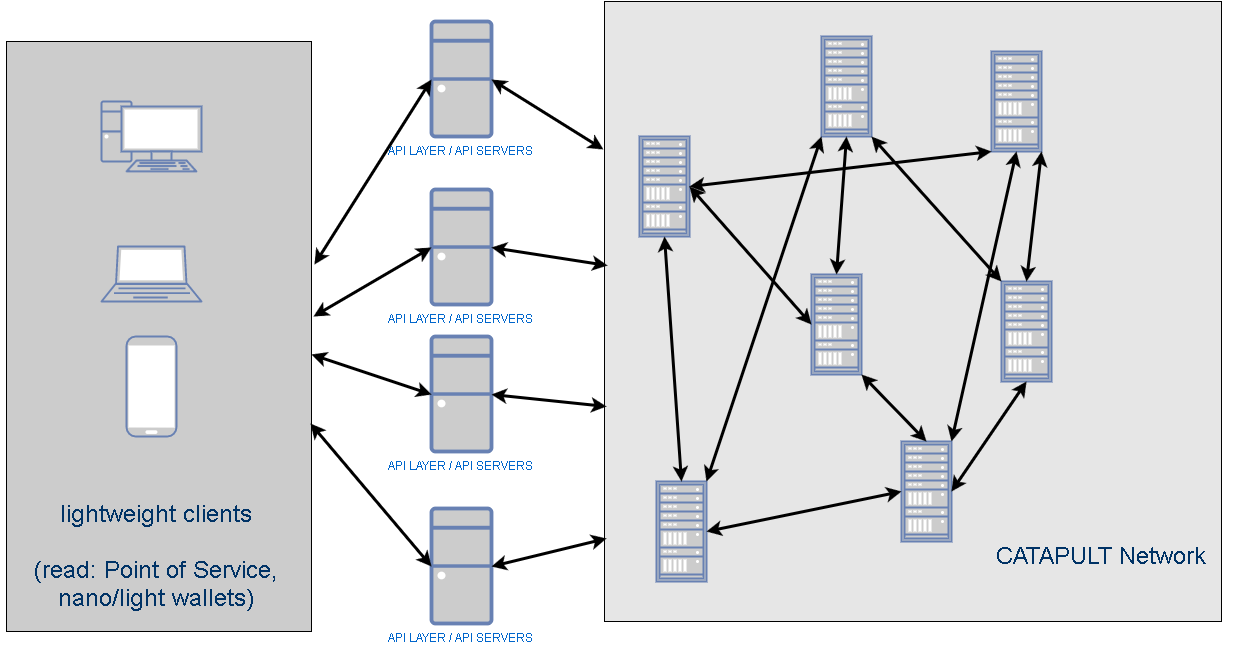
- api layer (catapult will have multi layer approach)
- support for all the transaction types
5 Likes
It can be concluded that the design follows the latest industry standard practice of aggregating and abstracting the APIs into a separate layer providing better maintainability, efficiency and service.
In trying to achieve maximum throughput, the design of the catapult is broken into application specific servers. A new layer of API servers is added so that it can allow the entire network to scale in both directions, i.e.,providing high throughputs (queries/s as well as tx/s through the API servers) while it also allows the backend network to scale independently.
The all new catapult network at the backend is where the blockchaining is. The whole idea of this type of configuration is to independently scale the API (the number of clients, and therefore the service level) and the blockchain (data replication / security). This sort of configuration allows for enterprise class deployment. They not only comply with industry practice, they also take NEM’s blockchain technology one notch up by being able to scale the number of transactions to thousands per sec. Initial results have been most promising. But the ninja boys are sharpening their wares to make it transact at even higher throughputs.
World class and bleeding edge in Blockchain technology design. Most promising indeed!
4 Likes
Is it Micro Service Framework?

over 1000tps , does it say that cultput will release soon
It says that Catapult is well on its way in development.
Looks like you are working on the API Server gateway now.
updated op
3 Likes
as far as I know, I haven’t seen anything like this on any blockchain. this is really forward thinking. not just thinking about how to scale a blockchain tx load. the reason is, if you do manage to get a billion tx a day, now you have another problem which is how to scale all that data to and from the light clients making those txs which would be A LOT. glad you guys are planning ahead.
1 Like
updated op 
1 Like
Thats awesome news! Thanks for the update.
If you need any testers, let me know, im happy to help
updated op 
how long is the interval between blocks?
Not sure how to read the timestamp
Interval between blocks is 15 seconds. Timestamp is in milliseconds from a predefined date.

To illustrate from block 11559 to 11560, there was a time lapse of (22512009059-22511991991)ms=17.068s. In this period, 59138 tx were performed. Hence, the transaction rate is 59138/17.068 = 3464.846 tps!!
1 Like