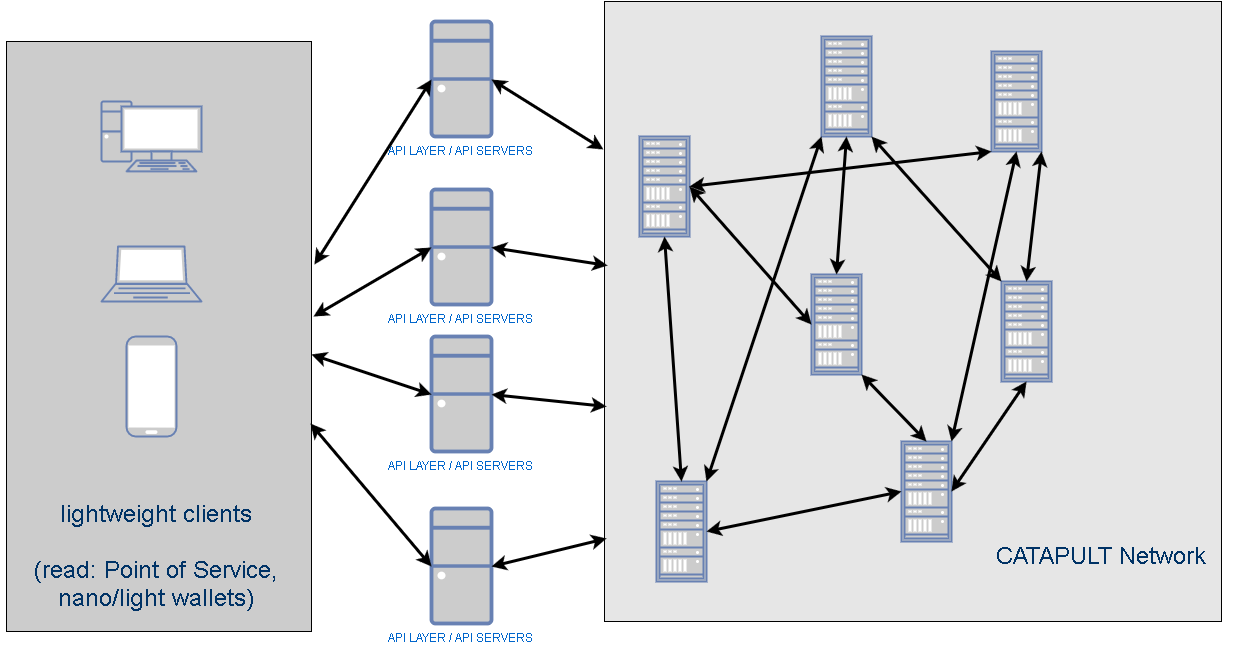
So we thought about starting short catapult related thread here.
Don’t expect constant or frequent updates, just some random msgs from us.
18th May 2018
If you somehow haven’t heard yet, we’ve published some initial version of both
catapult-server and catapult-rest.
Catapult-rest also has npm packages: https://www.npmjs.com/package/catapult-api-rest.
Mind that current version is not ready yet, to run public chain.
There are some precompiled docker images, but we’re waiting for some fireworks from TB, that will allow setting up network with a single click.
As you might have noticed I don’t update this thread so much, but I tweet from time to time.
28th Mar 2018
As mentioned of twitter, around 2 weeks ago we’ve slowly started next milestone (bison). 2 out of 3 parts of this milestone that we’ve already started are time synchronization and important memory optimizations, that are necessary to run public chain (we’ve barely started experiments, we’ll know bit more after that).
7th Feb 2018
We’re getting close to completing next milestone (alpaca). We’ve added two types of new lock transactions (if you’re asking, they are needed, but we reveal more details at some later point). Second part of the milestone is network discovery which is crucial for public network.
We’re slowly beginning to test the changes, and guys are adding support to new txes on sdk side.
12th Dec 2017
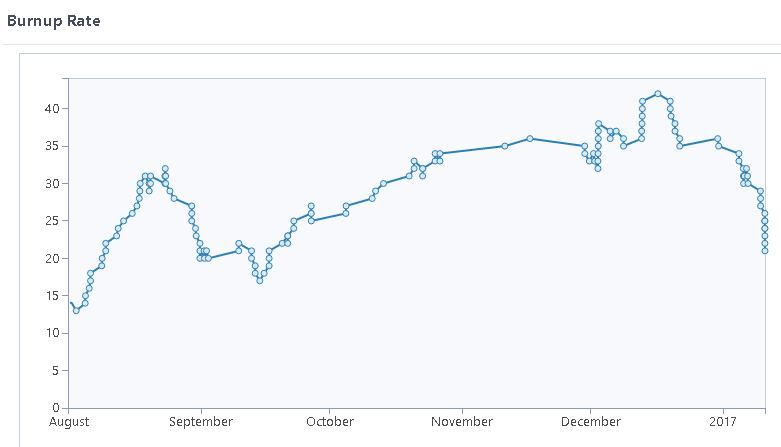
Just to keep you updated, some time ago @Jaguar0625 made some more order in our tasks, splitting them into alpha, and beta we’ve been trying to pay technical debt, here are some nice graphs for you with burnup rates
(tasks opened/closed)
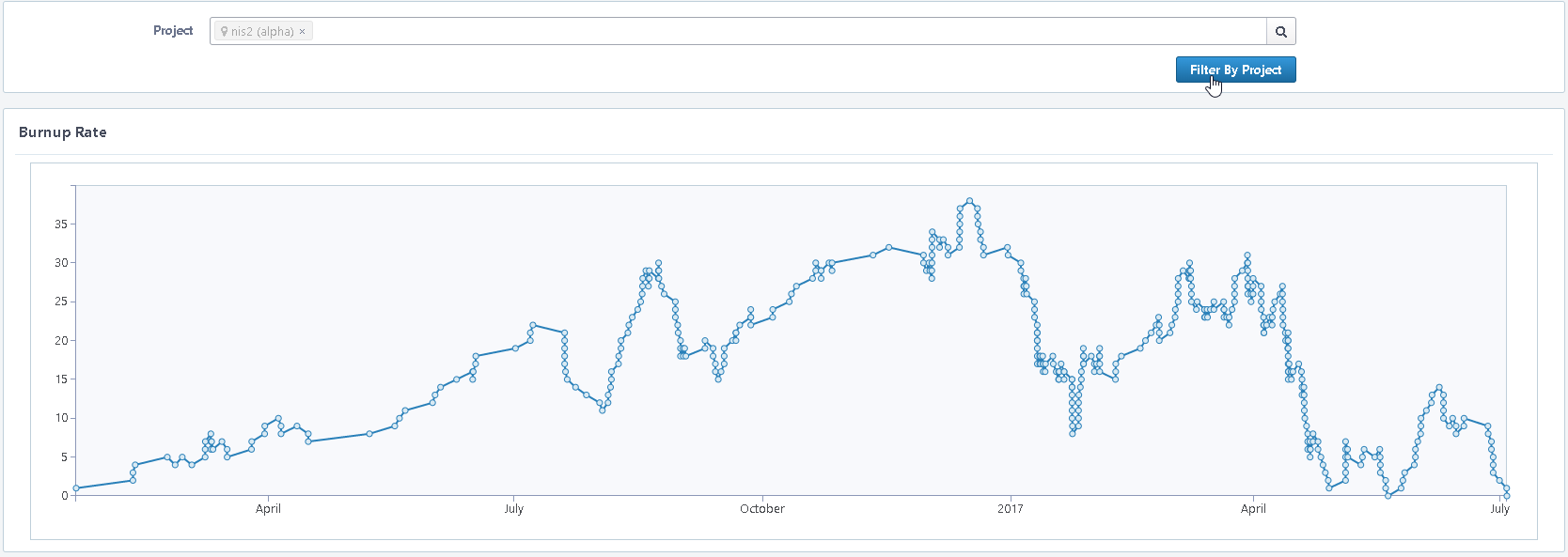
beta:

P.S. I bet there’s someone, who can try to nicely align them with some level of transparency ^^
1st Nov 2017
Long time, no hear, we actually had partial collector working for some time already. In the meantime issues has arisen, how to pass some of partial transaction related data to client apps. That’s more or less what we are pursuing now.
We’ve also found and fixed some bugs, @deleted_user_1 and @guillem have prepared e2e tests, are up to date with catapult-based low-level bindings for multiple languages that we’ll refer to as nem2-library.
1st Sep 2017
So it seems we’ve managed to finished failed transaction status collecting (that’s something that we needed, since transaction processing is a bit different in catapult, and there’s much more asynchronicity). Next thing on our list is so called “cosignatures collector” - this will be part of api server. More on that will probably be #soon in a separate post.
Also if you haven’t I post some shorter messages on twitter.
09th Aug 2017
We got basic support for websockets. We’re using ZMQ to pump data from api server to zmq endpoint where rest server listens. We should be able to do some testing of wallet supporting websockets this week.
In the meantime there were quite big internal changes when it comes to structure, thanks to this we’ll be able (in future) to change p2p and api servers just by switching some options – turning on and off some extensions.
25th Jun 2017
We’ve sort of finished secret feature and we’ve prepared deployment of an internal test network (shown to very limited group of people). Before we’ll be able to show it to a larger audience, we need websockets support (you don’t want to refresh wallet every time). That’s not as easy as it sounds as we have few competing ideas how to do it.
30th May 2017
Dear diary, I’ve missed the fact that we’ve hit 900 reviews, our latest has actually number 910.
We currently have over 7400 commits (excluding merges), gross of that belongs to Jaguar0625.
(number itself is actually bit higher as we sometimes squash the changes).
23th May 2017
Don’t have anything interesting to share, we were trying to reduce tech debt, it’s clearly visible on a burnup rate graph
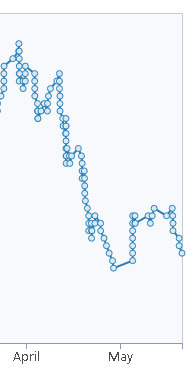
Jaguar made huge changes how validators and observers (think of it as transaction executors) work.
We slowly started working on multisig transactions, that part will be bit complicated (due to changes we’ve planned, and due to architecture changes), we will try to share some more details in future.
6th Apr 2017
We have some basic support for mosaics, although we don’t have levies yet. There will be some interesting changes regarding mosaics, although most likely they will be invisible from end user perspective.
Long time since I’ve pasted any cloc stats, so let’s go 
SRC (including tools)
Language files blank comment code
-------------------------------------------------------------------------------
C++ 266 3414 596 15439
C/C++ Header 420 4077 3420 13752
CMake 43 54 7 193
-------------------------------------------------------------------------------
SUM: 729 7545 4023 29384
TESTS
Language files blank comment code
-------------------------------------------------------------------------------
C++ 392 13402 9529 46586
C/C++ Header 105 1789 1576 6228
CMake 47 62 1 193
-------------------------------------------------------------------------------
SUM: 544 15253 11106 53007
total number of tests: ~4975
9th Mar 2017
We’ve added namespaces, and we were doing some initial tests of namespaces, we hope we’ll be able to wrap them up and start working on mosaics.
10th Feb 2017
Nothing fancy to report, we had some big structural changes due to plugins, @BloodyRookie did some heavy lifting of api node transation storage, both J and BR fixed some problems indicated in stress tests (IIRC, all problems were inside tests not inside the code), first plugin (transfer transaction) seems to be working.
We want catapult to have pluggable architecture, where one will be able to pick transaction types that are needed inside the network.
as a bonus burnup continuation of a previous graph
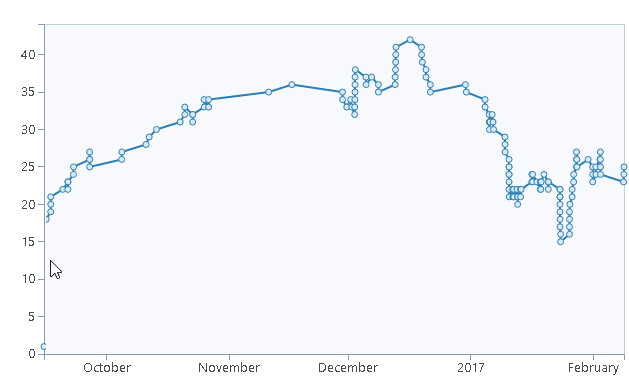
27th Jan 2017
This week we’ve started working on pluggable infrastructure and namespaces support.
10th Jan 2017
One of us (tip: not me ^^) has recently been busy with burning some tasks that accumulated
17th Dec
Just some testing before end of year

6th Dec
We have working e2e system (p2p nodes, api nodes, rest server).
We’ve started testing it. Obviously there are things that need fixing, but it’s pretty amazing everything
worked without much hiccup. Time spend on doing tests definitely paid of.
(obviously we’ll need much more testing, but it’s really good feeling)
We’ve also started adding websocket support to the rest server, so that we’ll be able to use nanowallet.
(we’re over 530 reviews, 2400 builds, 3800 tests, 260 rest server builds, 400 rest server tests)
24th Nov
I haven’t mentioned this earlier, but our architecture changed a bit. There will be 3 elements:
- P2P nodes - forming the backbone of the blockchain
- API nodes - similar to p2p nodes, but has different storage backend and it won’t take part in creation of the blockchain. It will save data for use in rest server
- REST server - to handle json api (client requests)
We’ve hit over 500 reviews. We’ve split rest part from api/p2p node part. We’d like to start testing using rest server

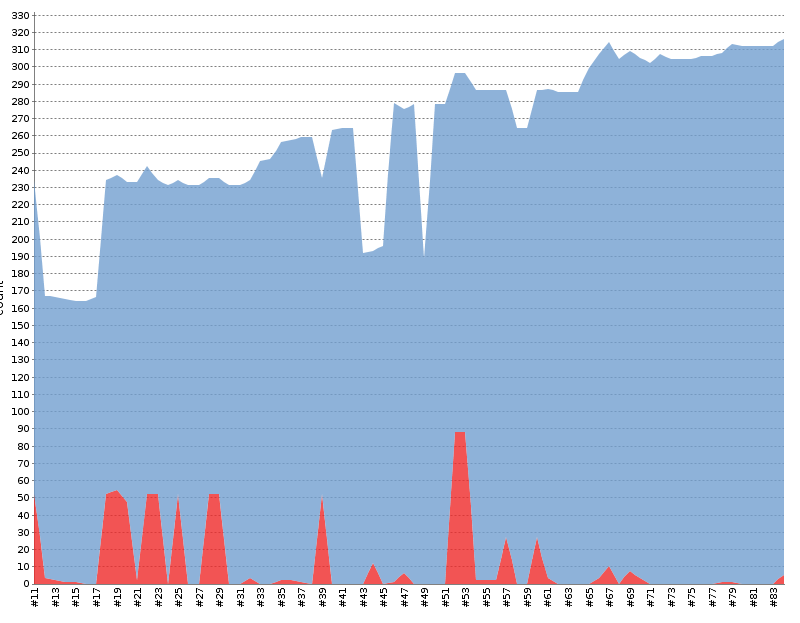
4th Nov
So we are “few” hundred builds later and almost 1000 more tests.
Our plans have changed a bit and for the last 3+ weeks we’ve been working on C++ part of api server.
14th Oct
We spent some time doing research work how to proceed with an API server.
Our current plan (and approach) is that api server will be running on top of node.js
(and will communicate with p2p nodes).
We started some basic work on the api server, more details #soonish.
In case you’re wondering “why nodejs?” - main purpose of api server is well - to serve APIs  so it’s generally good idea to reuse some existing server (we could have gone with ruby or with go, or put-your-favourite-platform-here, but since lightwallet and nanowallet are in JS, we will be able to share/reuse some of already existing code.
so it’s generally good idea to reuse some existing server (we could have gone with ruby or with go, or put-your-favourite-platform-here, but since lightwallet and nanowallet are in JS, we will be able to share/reuse some of already existing code.
25th Sep
some spamming ahead
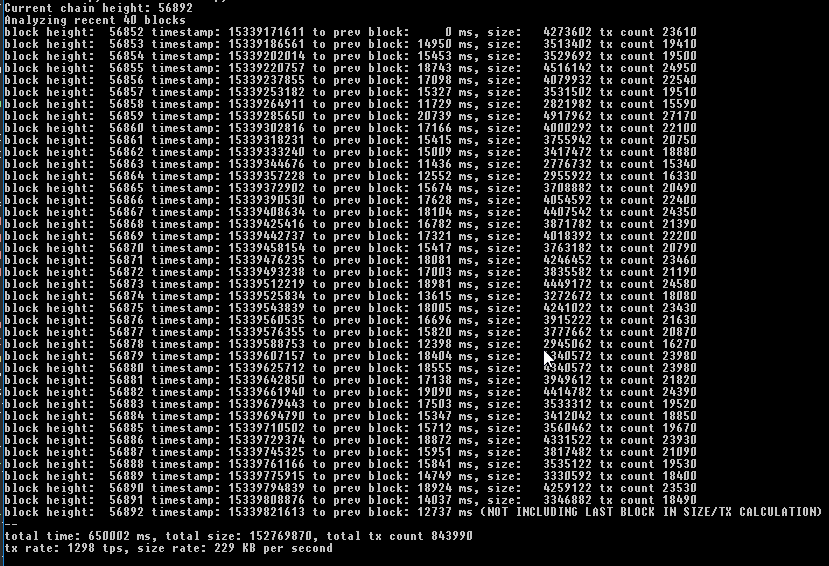
2nd Sep
SRC
Language files blank comment code
-------------------------------------------------------------------------------
C++ 131 1909 355 8759
C/C++ Header 213 2268 1908 7897
CMake 19 20 0 91
-------------------------------------------------------------------------------
SUM: 363 4197 2263 16747TESTS
Language files blank comment code
-------------------------------------------------------------------------------
C++ 227 7720 5501 28577
C/C++ Header 60 1163 888 4159
CMake 24 26 0 108
-------------------------------------------------------------------------------
SUM: 311 8909 6389 3284423rd Aug
SRC
Language files blank comment code
-------------------------------------------------------------------------------
C++ 124 1793 342 8274
C/C++ Header 203 2207 1846 7703
CMake 19 20 0 91
-------------------------------------------------------------------------------
SUM: 346 4020 2188 16068TESTS
Language files blank comment code
-------------------------------------------------------------------------------
C++ 218 7307 5233 27191
C/C++ Header 56 1091 840 3881
CMake 24 26 0 108
-------------------------------------------------------------------------------
SUM: 298 8424 6073 31180Our current number of tests is 3444
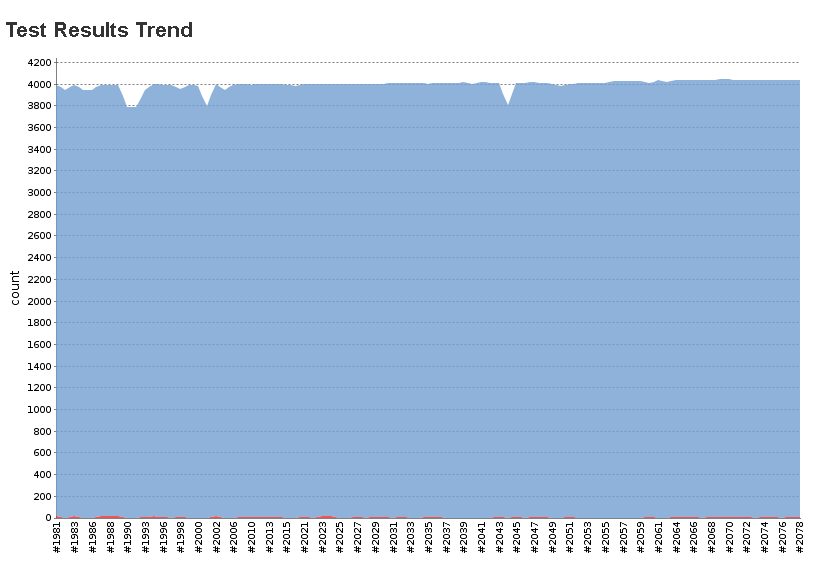
11th Aug
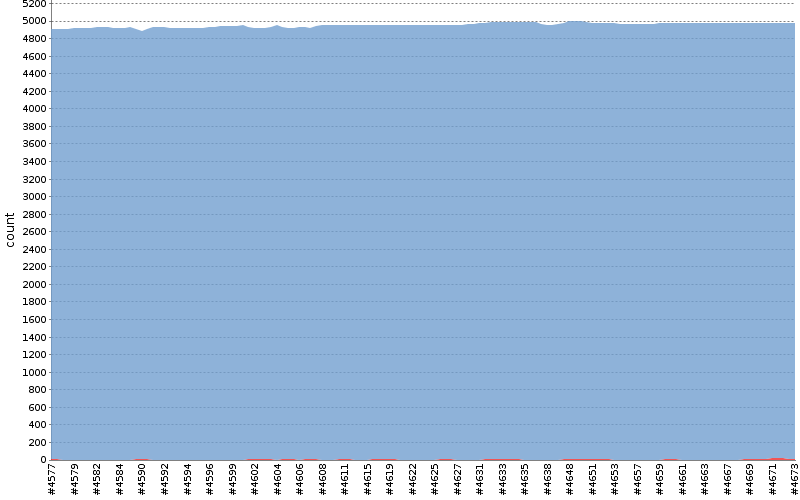
Some cool images for you from jenkins
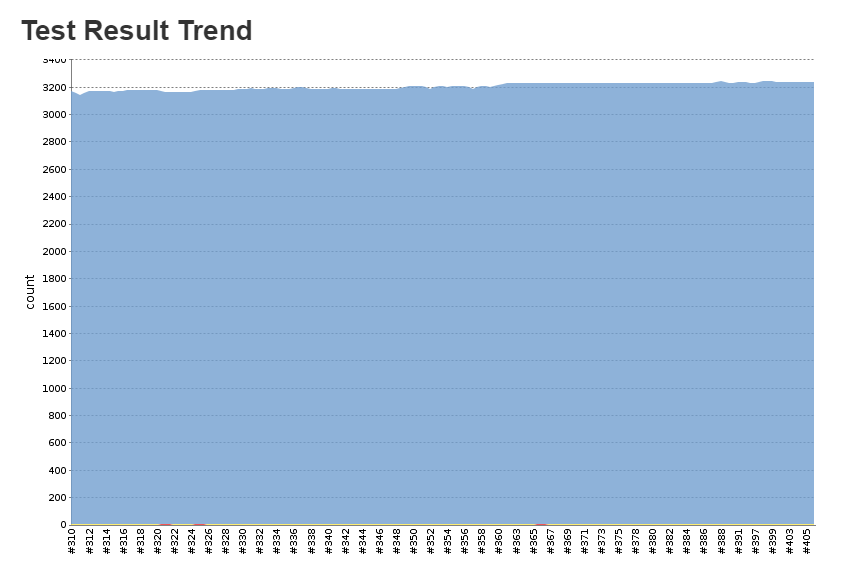
bottom axis is build number
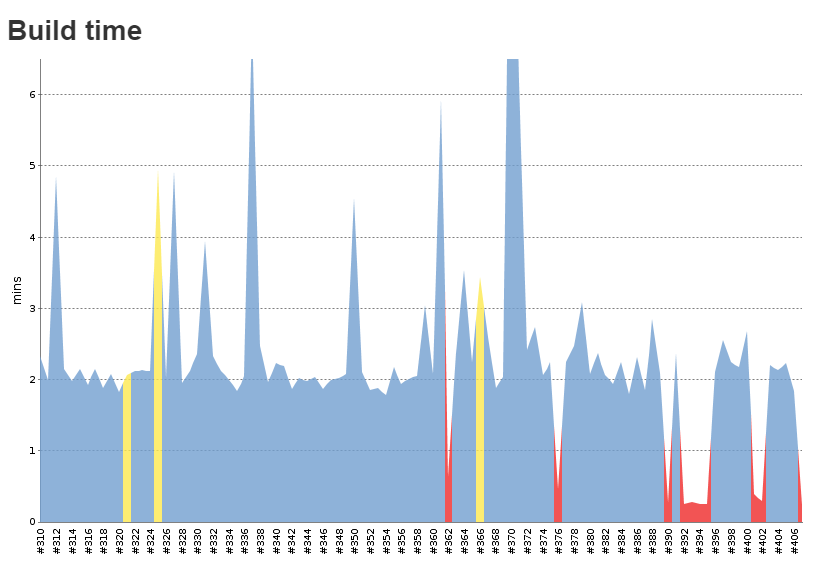
red ones are failed build (yeah that happens, as we’re using clang and VS, and build machine is using g++)
4th Aug
Today we have reached magic number of 256 reviews made.
3rd Aug
Updated code stats
SRC
Language files blank comment code
-------------------------------------------------------------------------------
C++ 115 1532 275 7062
C/C++ Header 182 1990 1652 6892
CMake 18 19 0 87
-------------------------------------------------------------------------------
SUM: 315 3541 1927 14041TESTS
Language files blank comment code
-------------------------------------------------------------------------------
C++ 199 6187 4545 23405
C/C++ Header 49 951 725 3308
CMake 23 25 0 108
-------------------------------------------------------------------------------
SUM: 271 7163 5270 26821Our current number of tests is 3137
27th Jul
We’ve recently switched build machine, on old one we’ve come to 2493 builds.
New one is now at build 75.
Our current number of tests is 2750 (more detailed stats some time later)
Some of you might have seen the image that we’ve leaked that shows catapult dependency graph http://imgur.com/rDzucbk
Over and out
10th Jun
SRC
Language files blank comment code
-------------------------------------------------------------------------------
C/C++ Header 131 1329 1040 4594
C++ 80 920 134 4206
CMake 13 15 0 63
-------------------------------------------------------------------------------
SUM: 224 2264 1174 8863TESTS
Language files blank comment code
-------------------------------------------------------------------------------
C++ 140 3910 3010 14838
C/C++ Header 36 484 308 1824
CMake 14 17 0 64
-------------------------------------------------------------------------------
SUM: 190 4411 3318 16726