
Full credit to mincoshi (@MIJ1024), who wrote the original Japanese article which you can find here
Introduction
In the last couple of versions, Catapult has presented some architectural changes in how various parts of the technology stack work together. With the current version of Catapult, 0.5.0.1 (Elephant), the functionality of the architecture is more “set in stone” so to speak, and these design choices will continue to make its way into the release candidate F milestone.
If you have run the Catapult Bootstrap by Tech Bureau, you can see several processes logging their activity at once. It illustrates how Catapult utilizes several different components to run the blockchain, and provide easy access for developers.
The purpose of this article is to clear up what these different components do, how they work together, and overall provide more insight into running your own Catapult node.
Please note that this article is specific to Catapult version 0.5.0.1 at the time of its writing.
Overall view
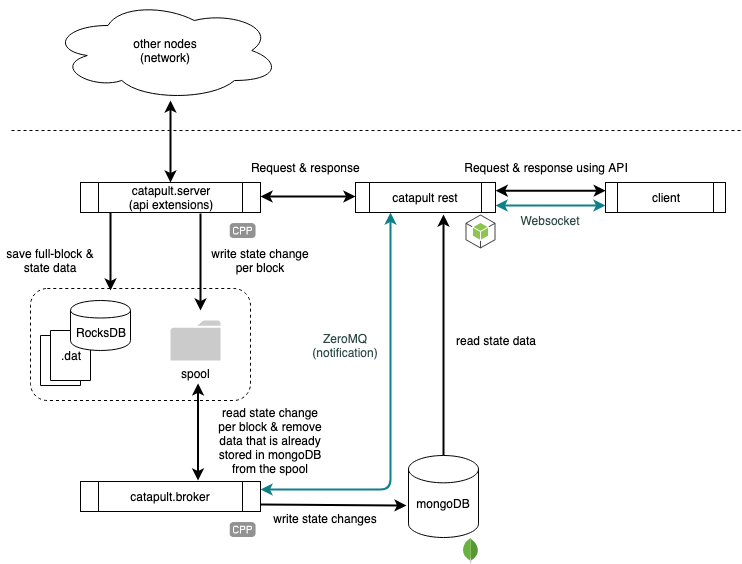
full credit to mincoshi for the diagrams
The figure above refers to the relationship between the Catapult API node and associated processes. Each component, the catapult.server, catapult.broker , and catapult-rest all work together asynchronously. Clients also react asynchronously to catapult-rest via websockets and the Reactive approach implemented in the Catapult SDKs.
The data flows from the catapult.server API portion to a file-based queue (called a spool).
which catapult.broker reads and deletes from accordingly. The catapult.broker then writes data to mongoDB, of which the catapult-rest process reads from and provides easy-to-use REST endpoints.
In total, this makes up four components (including mongoDB). Each of these parts are separate processes that may run on separate instances. For example, the catapult-service-bootstrap runs each of the four components in a separate Docker container, yet utilize the same set of directories with no issues:
// Log on excerpt when bootstrap is started
Creating docker_api-node-broker-0_1 ... done
Creating docker_db_1 ... done
Creating docker_peer-node-0_1 ... done
Creating docker_peer-node-1_1 ... done
Creating docker_api-node-0_1 ... done
Creating docker_rest-gateway_1 ... done
In this log from catapult-service-bootstrap, we can see two things happening:
-
Two peer nodes being initialized (
peer-node-0_1andpeer-node-1_1). These handle critical node tasks, like consensus. -
The four components mentioned earlier - mongoDB (
db_1), thecatapult.serverAPI node (api-node-0_1), thecatapult.broker(api-node-broker-0_1) and the catapult-rest instance (rest-gateway_1). These are used for API purposes.
Now that we have a general idea of how these components work together, we can break them down one by one for a better understanding:
catapult.server
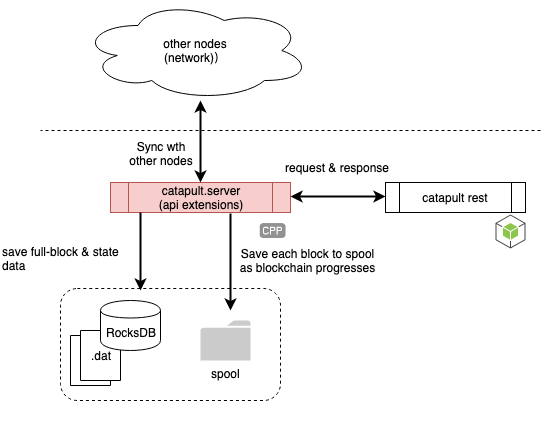
The catapult.server is the core of Catapult. It’s responsible for connecting to other nodes, consensus, and synchronization with other peers. catapult.server writes each block to the spool directory as the blockchain advances. catapult.server also accepts and confirms transactions from catapult-rest and returns information about the node itself.
catapult.broker
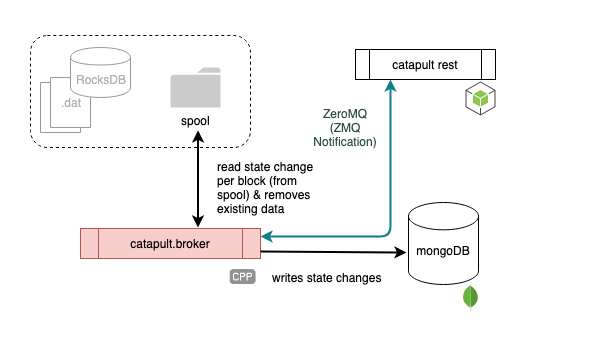
The broker aspect of Catapult is a relatively new addition to the Catapult stack. It was introduced in Dragon (0.4.0.1). and solves the previous bottleneck having to write to mongoDB after the API nodes have synchronized. Before this, catapult.broker was just another API extension included in catapult.server:
As one can see, ZeroMQ is used for efficient asynchronous messaging. This allows for a client to get blockchain state updates in real time. An interesting possibility with catapult.broker is its ability to possibly write to other kinds of databases in the future, allowing for more flexibility.
catapult-rest
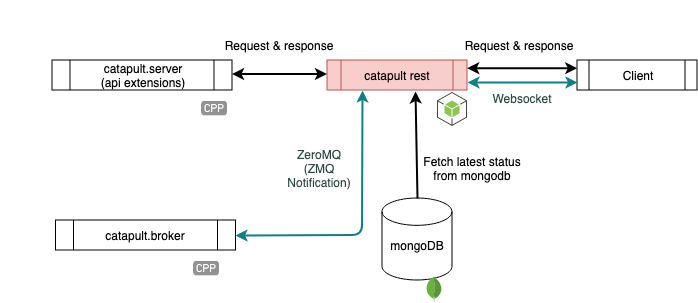
catapult-rest is the component developers interact with the most. Applications, like wallets, communicate directly to this REST gateway.
catapult-rest reads information directly from the mongoDB instance that catapult.broker writes to. catapult-rest also utilizes websockets, which in turn utilize catapult.broker's ZMQ async messaging to fetch state updates in real time.
As shown in the figure above, part of catapult-rest's functionality also includes propagating transactions from the client to catapult.server, where they confirmed and added to the chain.
The client
Clients are the “end users”, like wallets, web apps, and mobile apps that interact with the blockchain. Clients interact with catapult-rest through API calls and websockets.
Conclusion
This purpose of this article is to highlight the working nature of the Catapult stack. Each component works asynchronously to form a fast, efficient node that clients can easily interact with.
Having multiple moving parts to Catapult is actually an advantage. In NIS 1, the P2P and API nodes are combined into one; meaning a simple update would mean updating the entirety of the node’s software.
In Catapult, however, the abstraction of multiple processes allow for easy updates only certain parts of the stack, i.e, just to the REST layer without disturbing the core node software.
While this setup may seem complex, upon launch we will see that it will be packaged in an easy-to-approach manner.
Kudos to @MIJ1024 for this amazing article and breakdown of Catapult!
Links
Github repository
NEM Developer center
https://nemtech.github.io
Related Docs
https://nemtech.github.io/en/concepts/node.html
https://nemtech.github.io/en/server.html
Other miscellaneous link collection
https://github.com/mijinc0/my-catapult-docs/blob/master/reverse_lookup.md